DataSet

Method

Analysis
GitHub Repo
|
|
|
|
|
|
|
|
|
|
|
DataSet |
Method |
Analysis |
GitHub Repo |
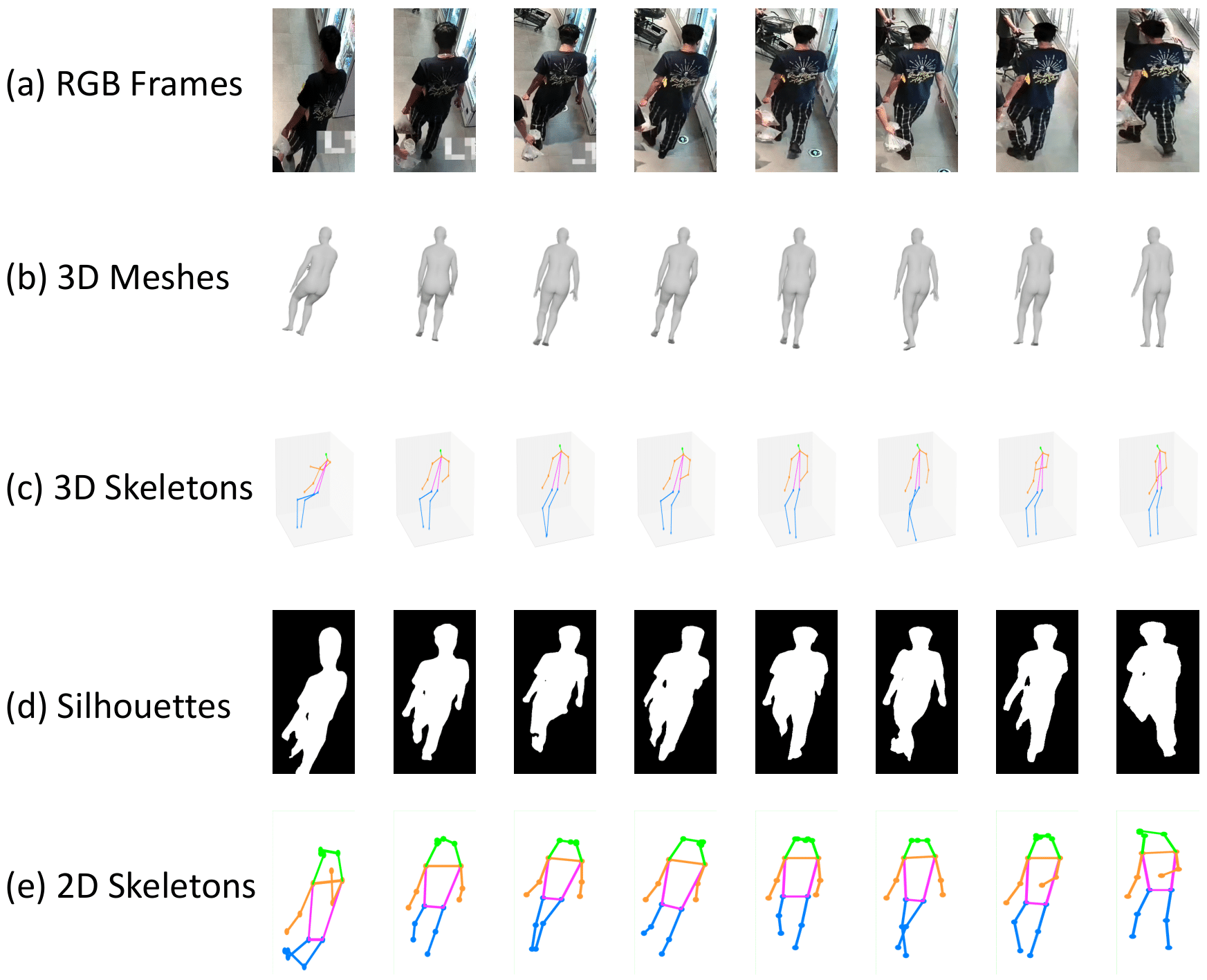
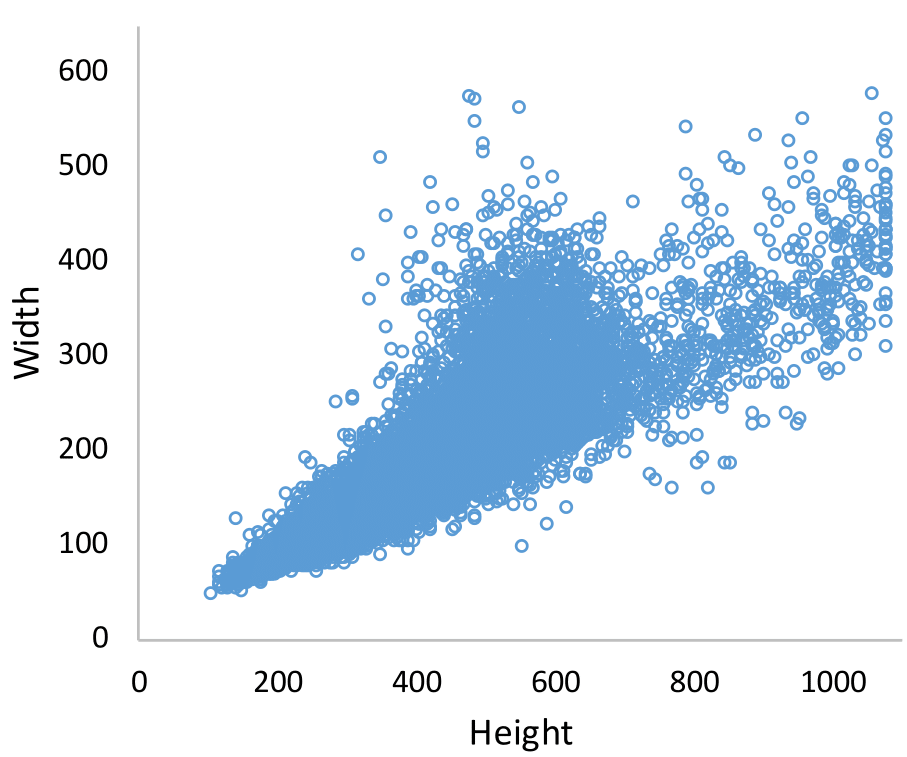
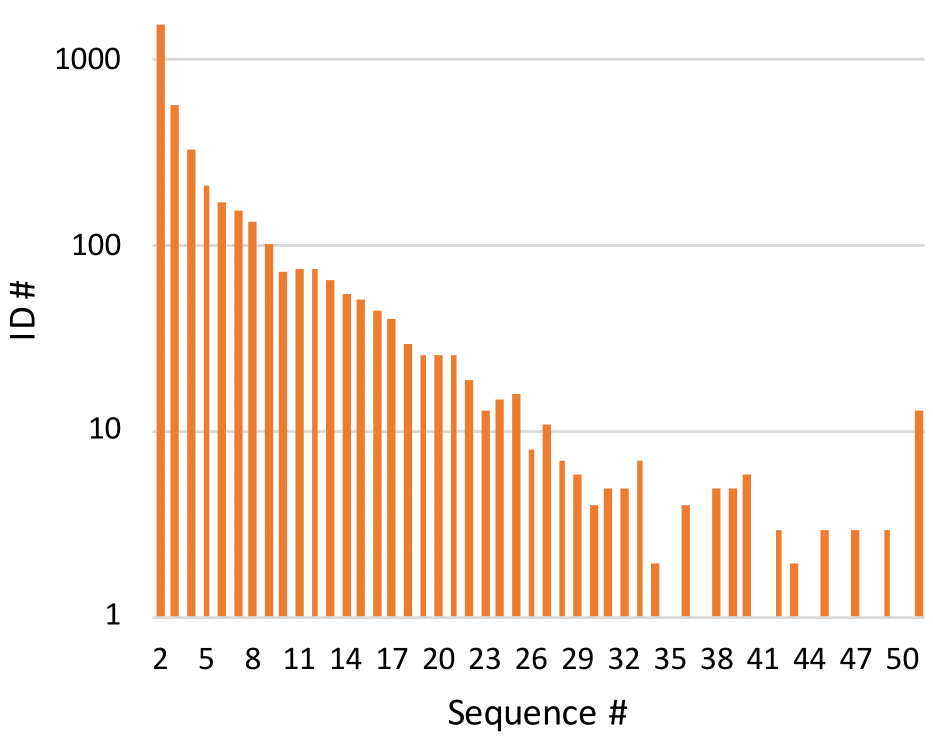
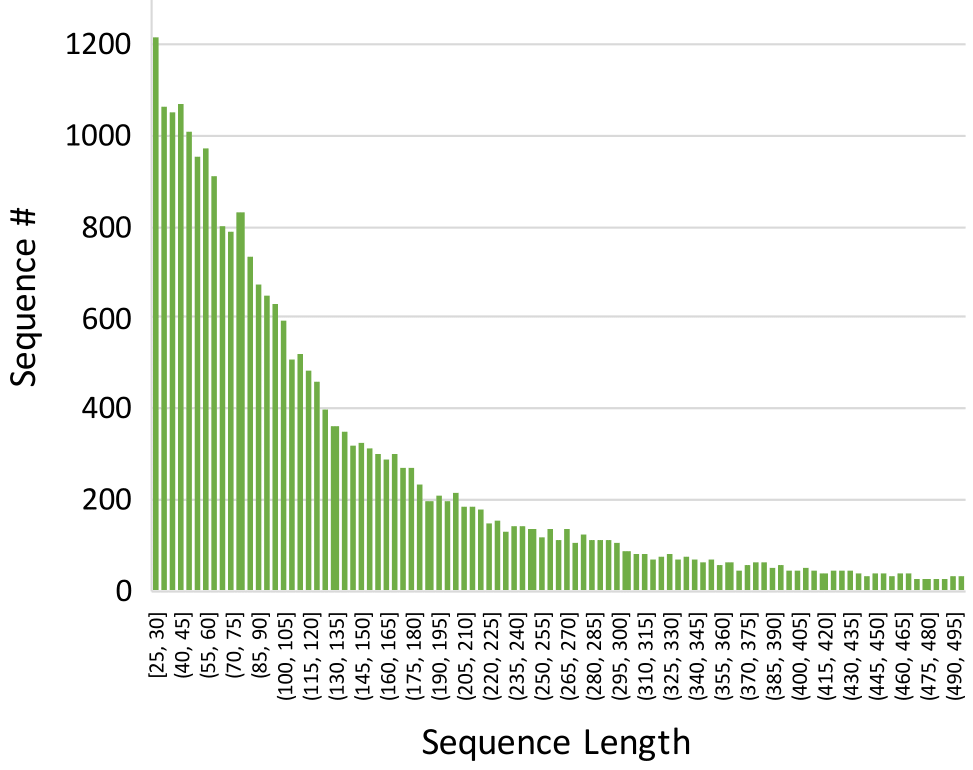
Existing studies for gait recognition are dominated by 2D representations like the silhouette or skeleton of the human body in constrained scenes. However, humans live and walk in the unconstrained 3D space, so projecting the 3D human body onto the 2D plane will discard a lot of crucial information like the viewpoint, shape, and dynamics for gait recognition. Therefore, this paper aims to explore dense 3D representations for gait recognition in the wild, which is a practical yet neglected problem. In particular, we propose a novel framework to explore the 3D Skinned Multi-Person Linear (SMPL) model of the human body for gait recognition, named SMPLGait. Our framework has two elaborately-designed branches of which one extracts appearance features from silhouettes, the other learns knowledge of 3D viewpoints and shapes from the 3D SMPLmodel. With the learned 3D knowledge, the appearance features from arbitrary viewpoints can be normalized in the latent space to overcome the extreme viewpoint changes in the wild scenes. In addition, due to the lack of suitable datasets, we build the first large-scale 3D representation-based gait recognition dataset, named Gait3D. It contains 4,000 subjects and over 25,000 sequences extracted from 39 cameras in an unconstrained indoor scene. More importantly, it provides 3D SMPL models recovered from video frames which can provide dense 3D information of body shape, viewpoint, and dynamics. Furthermore, it also provides 2D silhouettes and keypoints that can be explored for gait recognition using multi-modal data. Based on Gait3D, we comprehensively compare our method with existing gait recognition approaches, which reflects the superior performance of our framework and the potential of 3D representations for gait recognition in the wild. The code and dataset will be released for research purposes.
 |
 |
 |
 |
|
|
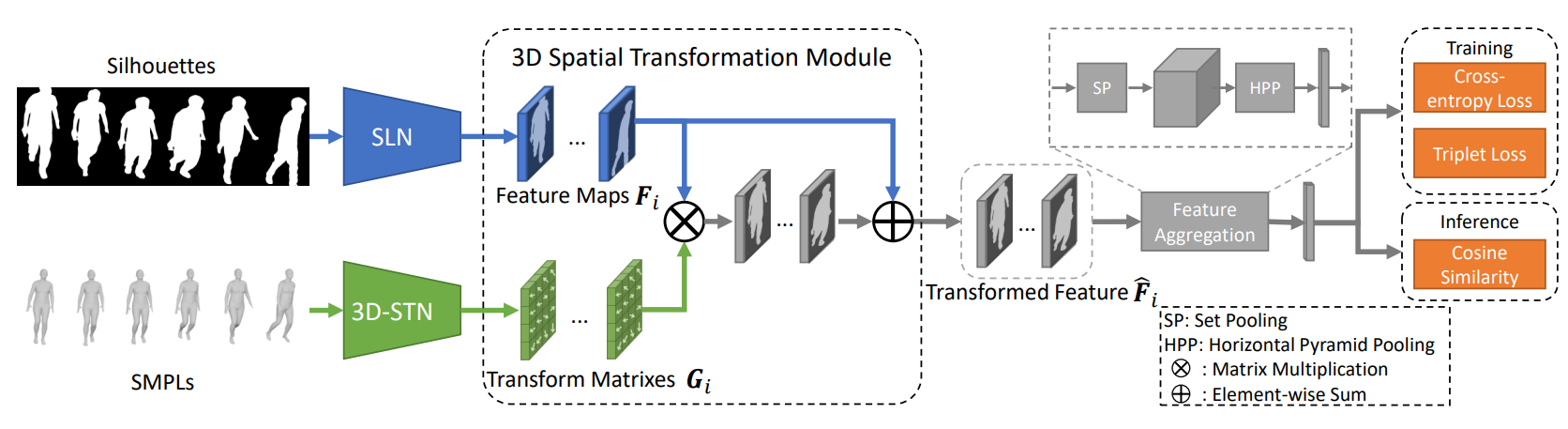 |
|
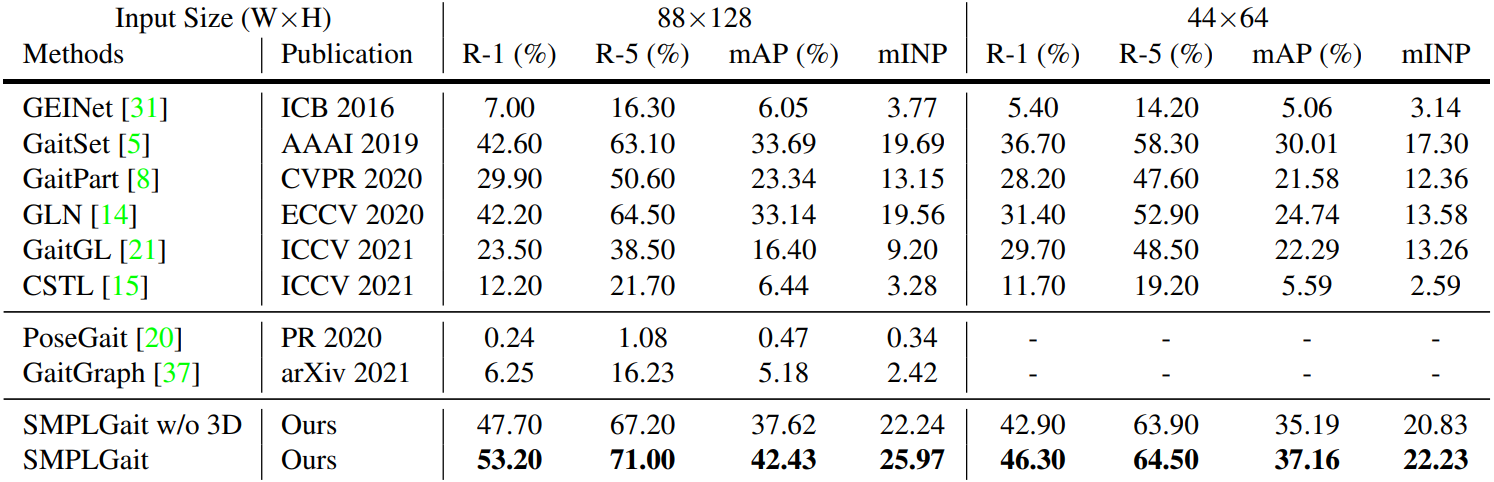 |
| Comparison of the state-of-the-art gait recognition methods on Gait3D. As the inputs of the model-based methods, i.e., PoseGait and GaitGraph, are unrelated to the frame size, we only report one group of results. |
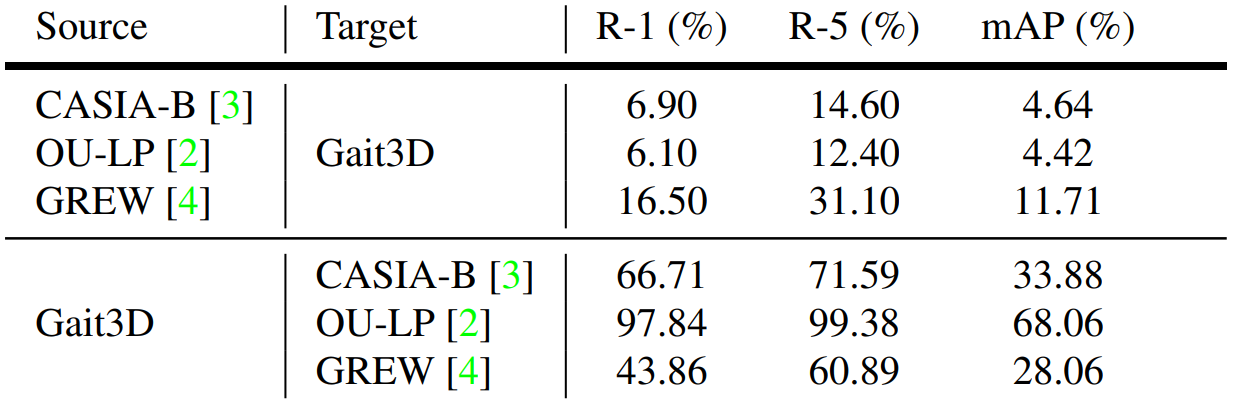 |
|
Results of cross-domain experiments. The method is trained on each source dataset and directly tested on the target datasets. |
 |
|
Exemplar results of SMPLGait on the Gait3D. 16 consecutive frames are sampled from each sequence for visualization. This case shows that our method obtains good results when the samples are high-quality. (Best viewed in color.) |
 |
Zheng, Liu, Liu, He, Yan, Mei. Gait Recognition in the Wild with Dense 3D Representations and A Benchmark In CVPR, 2022. (arXiv) |
 |
(Supplementary)
|
Contact |